
Últimamente seguro has escuchado bastante sobre los data warehouses en la nube. Quizás lo mencionaron en una reunión. O lo viste en una oferta de trabajo y pensaste, «debería saber qué es eso». Tranquilo, estás en el lugar correcto.
Hoy vamos a hablar de AWS Redshift. Es el almacén de datos que Amazon usa para procesar volúmenes gigantes de información. Pero no te preocupes, lo vamos a explicar sin complicaciones. Esto es más tipo «reunión con patas» que “presentación corporativa con slides”.
Vamos directo al grano.
¿Qué es AWS Redshift?
Imagina un depósito virtual enorme. Pero en lugar de estar lleno de cosas viejas como bicicletas oxidadas o herramientas olvidadas, está lleno de datos bien ordenaditos. Ese es Redshift.
Es un data warehouse en la nube que te permite hacer consultas rápidas y generar reportes sobre conjuntos de datos grandes sin sufrir en el intento.
¿Quieres saber qué productos están comprando más tus clientes? ¿O cómo te fue en ventas el último trimestre? Redshift está hecho para responder justo esas preguntas.
A nivel técnico, Redshift te deja organizar grandes volúmenes de datos y hacer consultas SQL para sacar insights. Y lo mejor: es completamente gestionado. AWS se encarga de los servidores, las actualizaciones, el escalado… tú solo te enfocas en los datos.
¿Quién más está compitiendo en este campo?
Redshift tiene competencia fuerte. Aquí algunos de los más conocidos en el mundo del data warehousing en la nube:
- Google BigQuery: súper escalable y con consultas rapidísimas.
- Snowflake: el favorito por su facilidad y soporte multi-nube.
- Azure Synapse Analytics: la propuesta de Microsoft, que se integra bien con sus otros servicios.
Todos tienen lo suyo. Pero hoy vamos con Redshift.
¿Por qué elegir Redshift?
Te doy algunas razones claras:
- Escalable: ¿Tus datos crecen? Redshift crece contigo. Agrega más poder con unos clics.
- Rápido: Está optimizado para velocidad. Las consultas pesadas vuelan.
- Económico: Solo pagas por lo que usas. Empieza chico y escálalo cuando lo necesites.
- Bien integrado: Se lleva de maravilla con S3 para almacenamiento, QuickSight para visualización, y todo el ecosistema de AWS.
Hora de la práctica: Configura Redshift Serverless
Listo, basta de teoría. Vamos a ensuciarnos un poco las manos y a levantar un entorno usando Redshift Serverless. Lo chévere es que AWS te da 300 dólares de crédito si nunca lo has usado. Perfecto para experimentar sin miedo a la factura.
Paso 1: Inicia sesión en AWS
Anda a aws.amazon.com. Si ya tienes cuenta, entra. Si no, créate una. Es rápido. Si estás en una empresa, usa una cuenta de pruebas o sandbox para no meter la pata en producción.
Paso 2: Busca Redshift
Dentro de la consola de AWS, escribe “Redshift” en el buscador. Haz clic en el resultado y luego elige Probar Redshift Serverless.
Así puedes crear tu warehouse sin preocuparte por configurar clústers ni nodos.
Paso 3: Crea tu Namespace
Ahora empieza lo bueno. Con Redshift Serverless no necesitas elegir tipos de nodo ni configurar clústers. AWS se encarga de todo eso por ti.
Vas a ver dos opciones:
- Personalizar configuración
- Usar configuración predeterminada
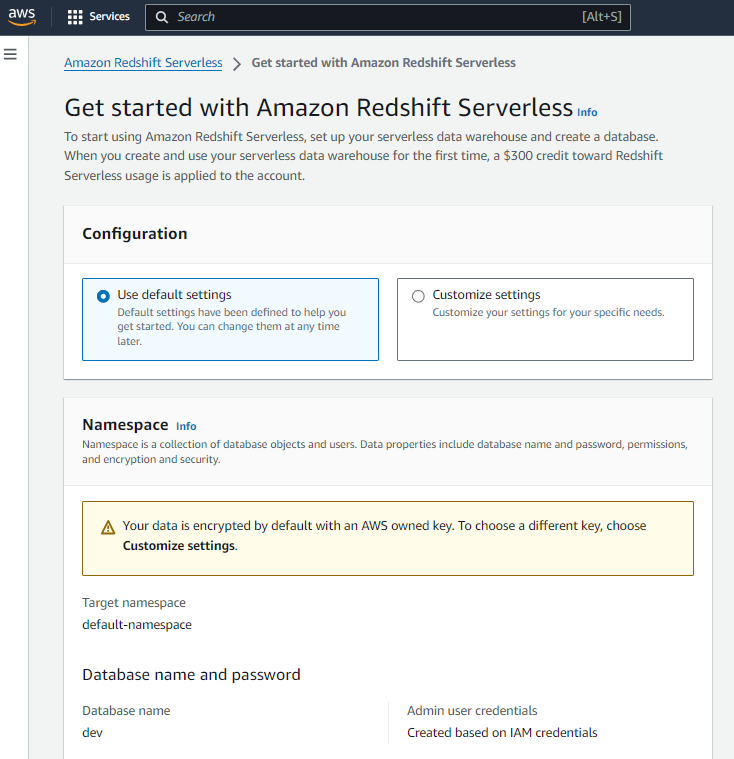
Para mantenerlo fácil, elige usar configuración predeterminada(Use default settings). Esto va a crear un namespace llamado default-namespace. No lo podrás cambiar, pero está bien para comenzar. Deja que AWS haga el trabajo pesado mientras tú aprendes cómo funciona.
¿Y qué es un namespace?
Piénsalo como tu centro de mando de datos. Ahí viven tus tablas, se ejecutan tus queries, y pasa toda la magia. Sin servidores que gestionar ni configuraciones raras. Solo un espacio limpio para trabajar a gusto.
Es como tener una cocina de lujo. Tú solo cocinas tus recetas de datos y AWS se encarga de lavar todo al final. Nada mal, ¿no?
Lo que viene: Algunas configuraciones más
Antes de lanzar todo, hay un par de cositas que ajustar. Nada complicado. Solo unos clics más y estás listo.
1. Nombre de la base de datos y contraseña
Por defecto, Redshift Serverless crea una base de datos llamada dev. Si usaste la configuración predeterminada, no podrás cambiarle el nombre. Y está bien así.
El usuario admin también se crea automáticamente. No tienes que hacer nada. La contraseña se gestiona con tus permisos de IAM, así que solo asegúrate de tener acceso correcto desde tu cuenta de AWS.
2. Roles IAM asociados
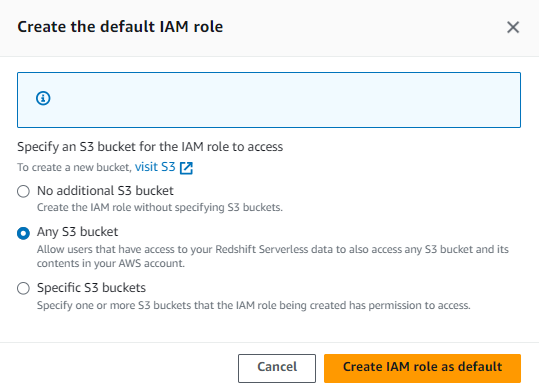
Esto sí es importante. Tu entorno de Redshift necesita permisos para hablar con otros servicios de AWS, como S3 si vas a cargar datos desde ahí.
- Crear o seleccionar un rol IAM: Verás una sección llamada IAM roles asociados. Si no tienes uno, haz clic en Crear IAM role. AWS te guía paso a paso.
- Permisos: Asegúrate de que el rol tenga la política
AmazonRedshiftAllCommandsFullAccess. - Asignarlo: Una vez creado el rol, selecciónalo y márcalo como predeterminado para tu namespace.
¿Por qué importa esto?
Piensa en el rol IAM como darle una llave maestra a tu warehouse. Sin esa llave, Redshift no puede acceder a tus buckets de S3 ni a otros servicios. Con esa llave, todo fluye sin dramas.

3. Configura el Workgroup
Ahora vamos con el workgroup. Si el namespace es tu cocina, el workgroup es la cocina industrial. Ahí se hace todo el procesamiento pesado.
Redshift lo usa para definir cuánta fuerza va a usar para ejecutar tus consultas.
Estos son los pasos:
- Nombre del workgroup: Aparecerá como
default-workgroup. Déjalo así. - Capacidad: Empiezas con 128 RPUs, suficiente para pruebas y consultas básicas. Puedes aumentarlo más adelante si hace falta.
- Red y seguridad: AWS configura todo automáticamente. Crea una VPC, subredes y grupos de seguridad. Déjalo tal como está salvo que tengas un motivo muy específico para cambiarlo.
Cuando termines, haz clic en Guardar configuración y seguimos.
4. Lanza tu entorno Redshift Serverless
Con el namespace y el workgroup configurados, dale a Continuar.
Redshift Serverless empezará a levantar tu entorno. Puede tardar un par de minutos, así que aprovecha para estirarte o prepararte un café.
Lo genial es que acá no hay clústers clásicos ni nodos para elegir. Todo corre bajo el capó usando tu namespace y tu workgroup.
Cuando esté listo, ya puedes empezar a cargar datos y lanzar tus primeras queries. Con Redshift Serverless, ya no existe el concepto de un clúster tradicional, trabajarás con tu namespace y workgroup en su lugar. Una vez que el entorno esté listo, ¡es hora de empezar a usarlo!
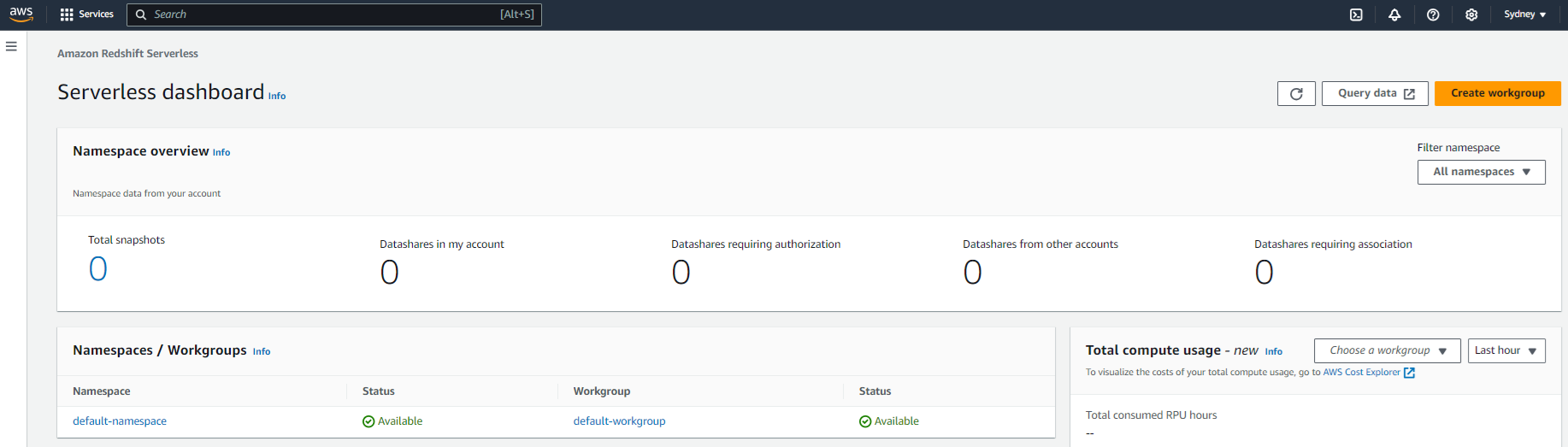
5. Conéctate a tu Namespace
Una vez que el entorno esté activo, es momento de conectarse.
La forma más fácil es usar Query data, también llamado Query Editor v2, desde la consola de Redshift. Corre en el navegador, sin necesidad de instalar nada. Pero si prefieres usar SQL Workbench o pgAdmin, también puedes.
Pasos para conectarte desde el editor:
- Entra a los detalles de tu namespace
- Haz clic en Query data
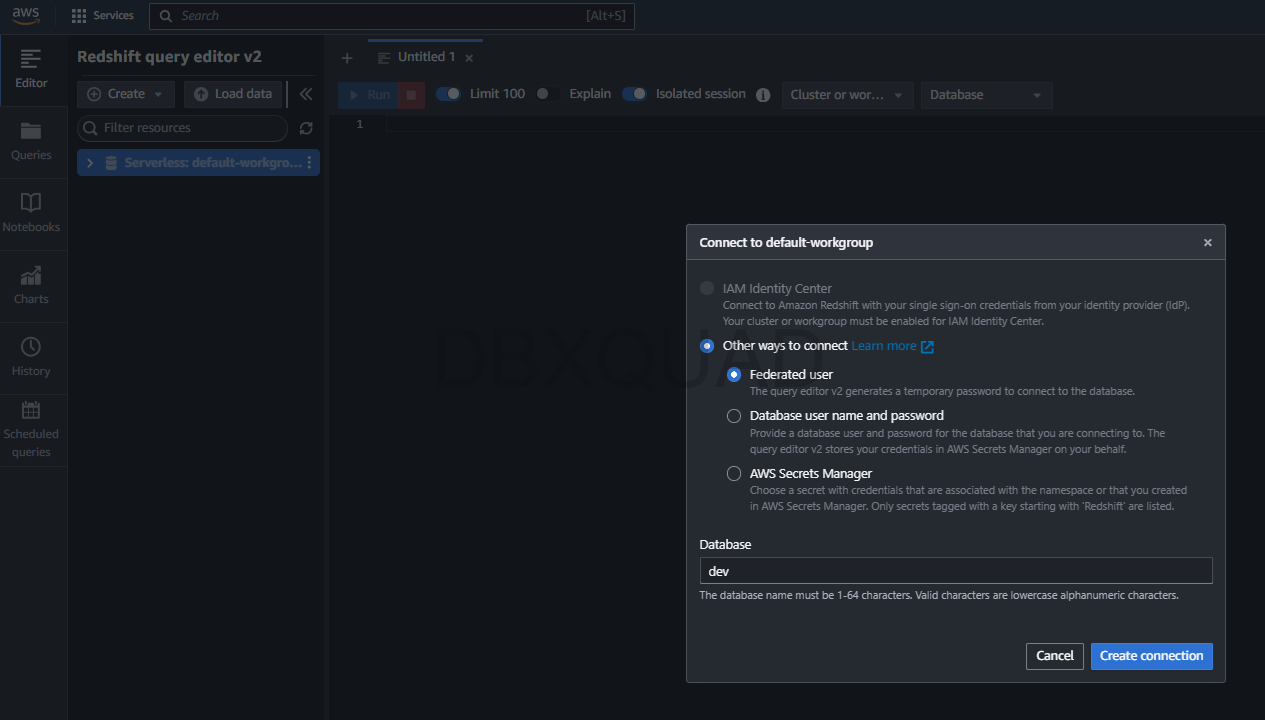
- A la izquierda verás algo como Serverless: default-workgroup. Haz clic
- Te saldrá una ventana que dice Conectarse a default-workgroup. Ya estará seleccionada la base
dev - Haz clic en Crear conexión y listo
6. Crea una tabla y carga algunos datos
Ahora que estás dentro de la base dev, crea una tabla para guardar los datos de un CSV.
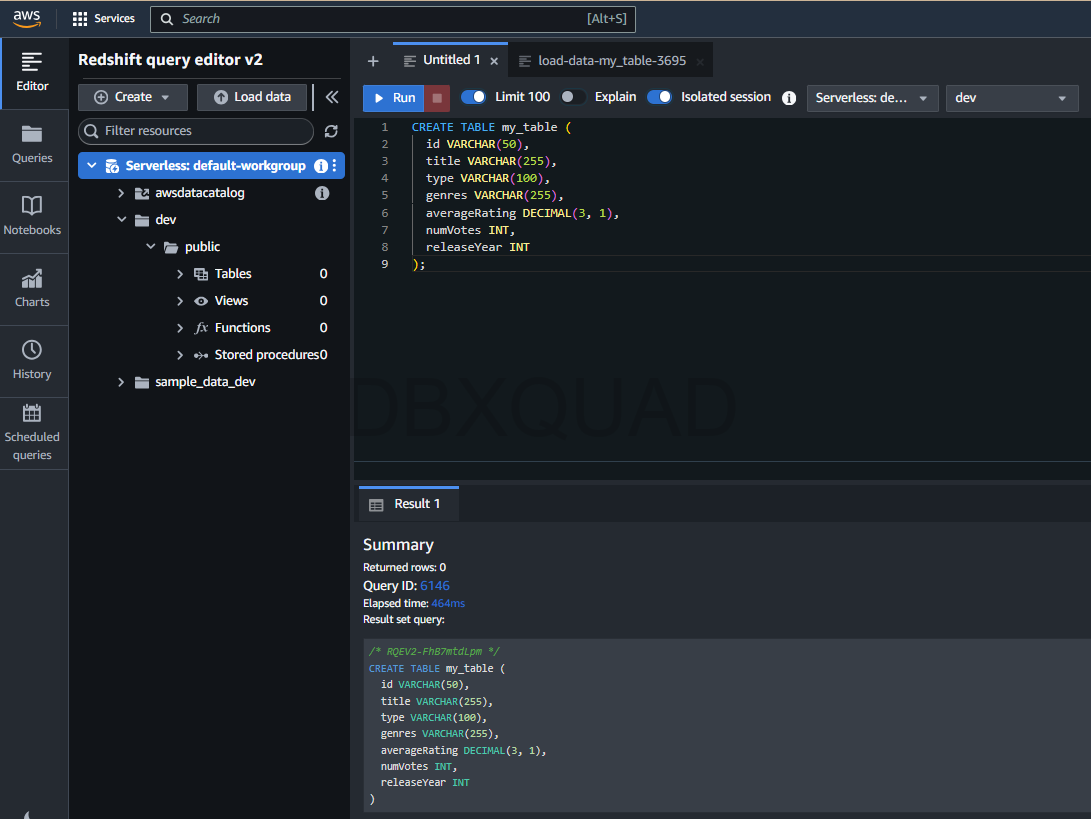
- Crear una tabla: Usa el siguiente comando SQL para crear una tabla:
CREATE TABLE my_table (
id VARCHAR(50),
title VARCHAR(255),
type VARCHAR(100),
genres VARCHAR(255),
averageRating DECIMAL(3, 1),
numVotes INT,
releaseYear INT
);Este esquema está diseñado para alinearse con la estructura del conjunto de datos de IMDB, con tipos de datos apropiados para cada columna.
Ahora que tenemos una tabla lista, ¡vamos a cargar algunos datos! Utilizaremos un archivo CSV de Kaggle, y eres libre de crear una cuenta en Kaggle o usar un conjunto de datos que hemos preparado para hacerte la vida más fácil. Puedes encontrar el conjunto de datos aquí: IMDB Full Dataset. Redshift Serverless puede extraer datos directamente de AWS S3, así que una vez que tengas el CSV, puedes copiarlo fácilmente a Redshift.
- Sube tu archivo CSV a un bucket de S3.
- Usa el comando
COPYpara cargar los datos en Redshift. Aquí tienes un ejemplo de comando:
COPY my_table
FROM 's3://my-bucket-name/my-file.csv'
IAM_ROLE 'arn:aws:iam::your-iam-role'
FORMAT AS CSV
DELIMITER ','
QUOTE '"'
IGNOREHEADER 1;Solo reemplaza my_table, my-bucket-name y your-iam-role con tus detalles reales.
7. Ejecuta algunas consultas
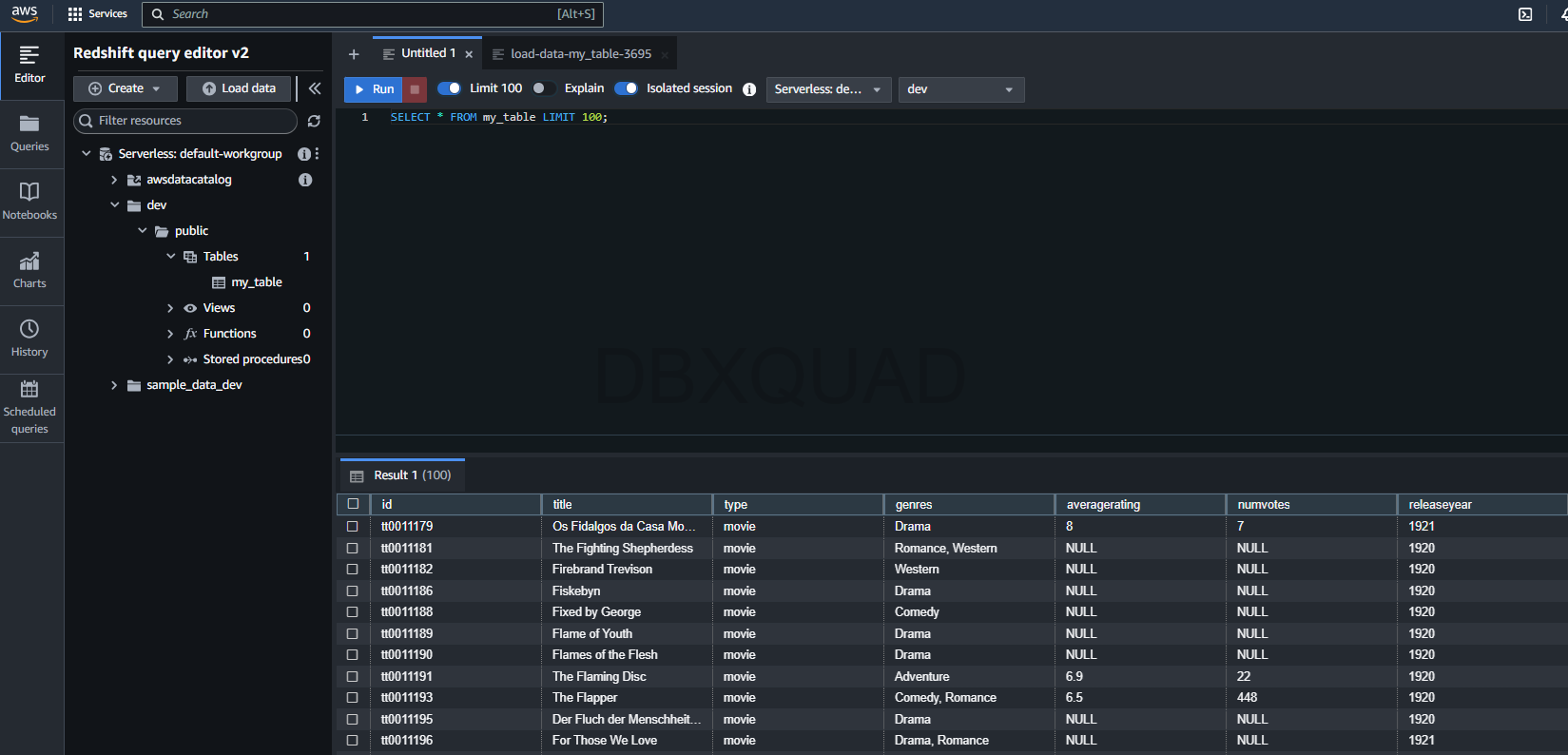
Ahora que la tabla tiene datos, puedes lanzar una consulta sencilla:
SELECT * FROM my_table LIMIT 100;Esto te mostrará las primeras cien filas de tus datos, como un adelanto para asegurarte de que todo se vea bien. Query Editor v2 hace que sea fácil ejecutar consultas y ver tus resultados al instante.
Consejo Final: Evita Cobros Innecesarios
Antes de cerrar todo y sentirte un máster del data warehousing, hay algo que no deberías olvidar.
Aunque Redshift Serverless escala solo, si dejas el entorno corriendo, te puede seguir cobrando. Mejor eliminarlo cuando termines.
¿Qué hacer?
- Ve a la consola de Redshift
- Borra el namespace y el workgroup
Así te aseguras de no pagar por recursos que ya no estás usando. Fácil y sin sorpresas.
Para cerrar
Y listo. Acabas de crear tu primer entorno con Redshift Serverless, cargaste datos y lanzaste queries como todo un pro.
Este servicio es potente, escalable, y bastante amigable para quienes recién comienzan. No necesitas ser una gran empresa para usarlo. Si tienes datos y preguntas, Redshift está listo para ayudarte a encontrar respuestas.
Ahora cierra tu laptop, relajate y celébralo 🎉